Structuring tourism data for the semantic web.
Data for humans…but not (yet) for machines.
About 30 years ago, Tim Berners-Lee invented the World Wide Web (Web for short). In order to sort and link content of all kinds (text, images, audio, video files, etc.), he developed a system that identifies them by URLs. These URLs are still used today to link from one document to any number of others. This creates a network of documents or websites – the World Wide Web.
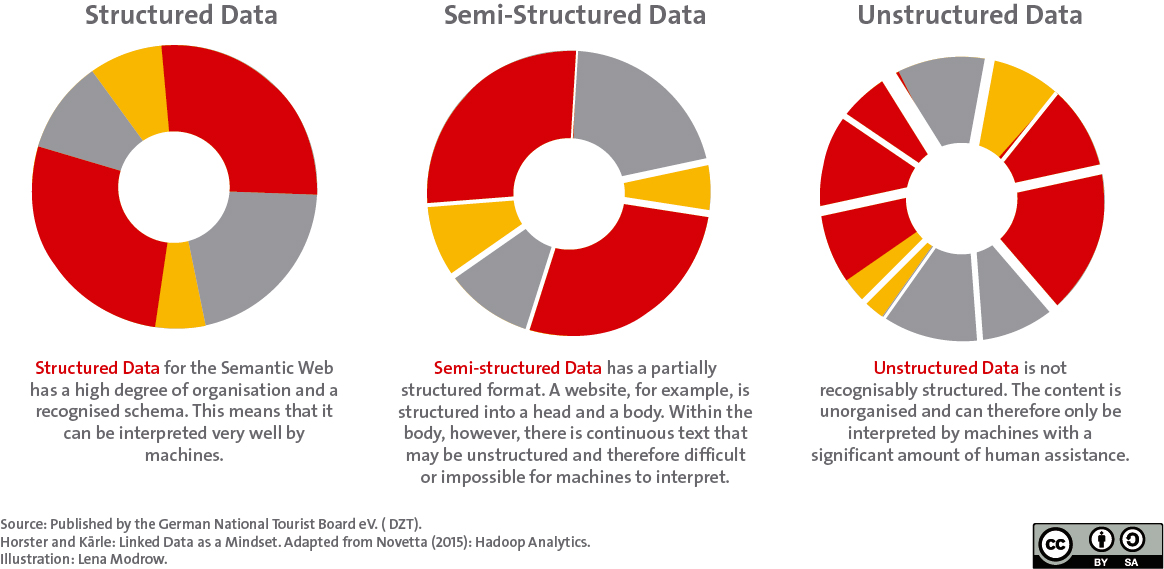
Content on the web is generally easy for people to read. However, machines still reach their limits when it comes to interpreting the contents. This is mainly due to the fact that they are offered in an unstructured or semi-structured way (see infobox). For example, the description of a cycling tour can be a be “broken down” into its component parts and aspects such as: distance, duration, altitude, difficulty, etc. are taken into account in a list. In the same way, however, all this information could also be described and provided in a single coherent text.
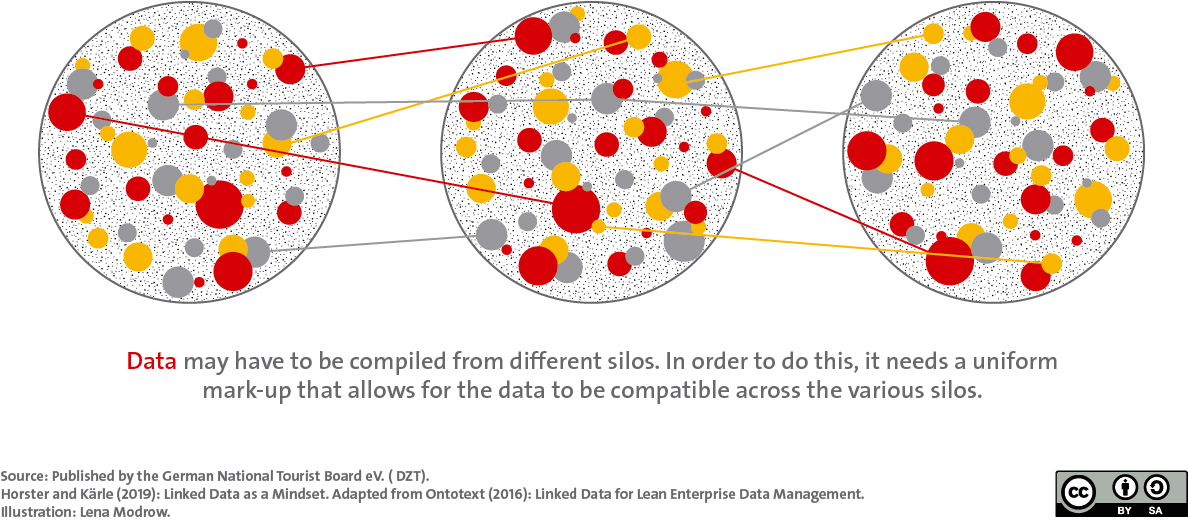
Overcoming data silos
Data can be structured very heterogeneously and usually are in German tourism. Machines cannot easily decipher these differences. If data is also to be processed for machines, this requires uniform data labelling: each cycle path would have to be described in the same way.
Then the labeling logic would be immediately understandable and the data of different cycle paths can be combined from different data sources (data silos).
This idea of describing the data structure in a uniform way and then connecting it is called Linked Data. Tim Berners-Lee explained this further development of the web very clearly in a TED talk that is still groundbreaking today:
Linked data can therefore be used to combine information from different contexts. Descriptions of cycling tours would no longer have to end at administrative boundaries, but could be continued via a uniform structure of data for the guest.
Linked Data is the key
Currently, there is still a strong human orientation in the processing of data in tourism. When information about a bike path is filed, it is usually done with the goal of publishing it in a particular app or on a website for one’s guests. In principle, there is nothing wrong with that.
However, it will become increasingly important in the future to provide data in such a way that it can be used universally outside of a specific use case. For this purpose, it is important that they are described in a uniform way with the help of an ontology. In tourism, these are schema.org and an extended vocabulary. The latter is currently being developed by a consortium (DACH-KG) specifically for tourism.
There is talk of “interoperability”: Data can be further processed by humans and machines independent of the output channel and also independent of the context. This has two primary backgrounds:
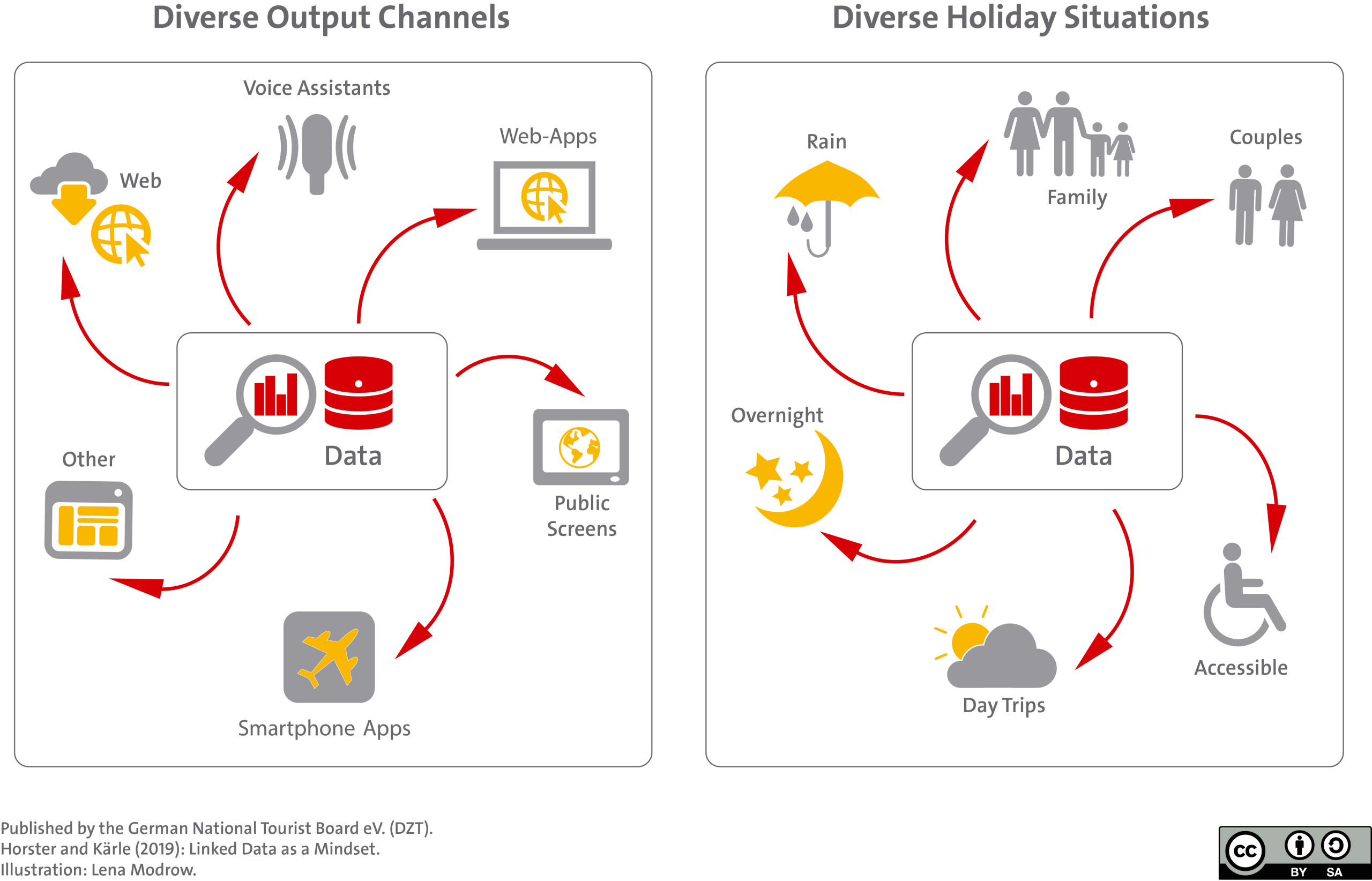
Data management as a task for the future
The Web is increasingly evolving from a web of linked documents to a web of linked records as a result of different requirements.
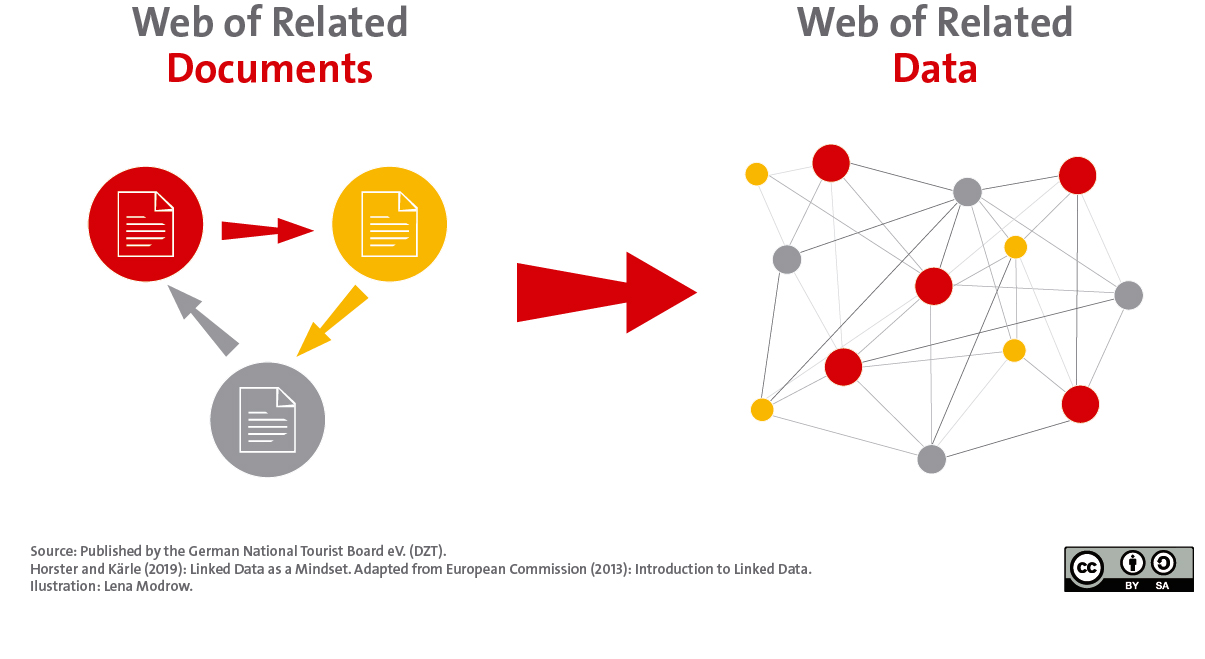
This adaptation of data management is highly relevant against the background of the development of the Internet of Things: By means of sensor technology, a great deal of context data on weather, time, states (empty or full, light or dark, etc.) will be available in the future. In combination with structured data on tourist POIs, events, etc., a wide range of applications can be created here. The vision here often goes in the direction of automated services that, depending on the holiday context (rain or shine, morning or evening, high or low season, etc.), make recommendations that suit both the situation and the guest in question.
At the latest now it becomes clear that a modern data management can be a central future task of the DMO. Specifically, this means that the focus of data management should be on the readability, interpretability, and usability of data for machines (and humans).

Eric Horster
West Coast University of Applied Sciences
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: http://eric-horster.de/

Elias Kärle
University of Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/