Die Strukturierung touristischer Daten für das Semantic Web.
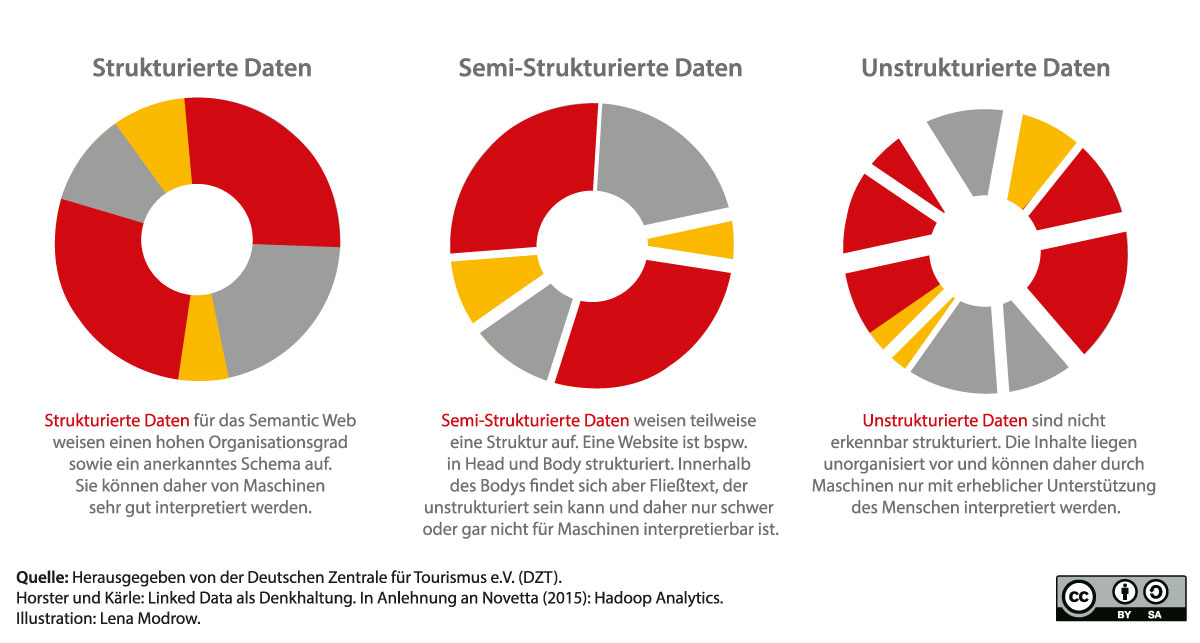
Daten für Menschen…aber (noch) nicht für Maschinen.
Vor rund 30 Jahren erfand Tim Berners-Lee das World Wide Web (kurz Web). Um Inhalte jeglicher Art (Text, Bild, Audio, Videodateien usw.) zu sortieren und miteinander zu verbinden, entwickelte er ein System das diese durch URLs identifiziert. Diese URLs werden bis heute verwendet, um von einem Dokument auf beliebig viele andere zu verweisen. Dadurch entsteht ein Netzwerk von Dokumenten bzw. Websites – das World Wide Web.
Inhalte im Web sind für Menschen grundsätzlich gut lesbar. Maschinen stoßen bei der Interpretation der Inhalte aber bis heute an ihre Grenzen. Das liegt vor allem daran, dass sie unstrukturiert oder semi-strukturiert angeboten werden (siehe Infobox). So kann die Beschreibung einer Radtour bspw. in ihre Einzelteile „zerlegt“ werden und in einer Liste Aspekte berücksichtigt werden wie: Strecke, Dauer, Höhenmeter, Schwierigkeitsgrad usw. Genauso könnten aber all diese Informationen auch in einem einzigen zusammenhängenden Text beschrieben und bereitgestellt werden.
Überwindung der Datensilos
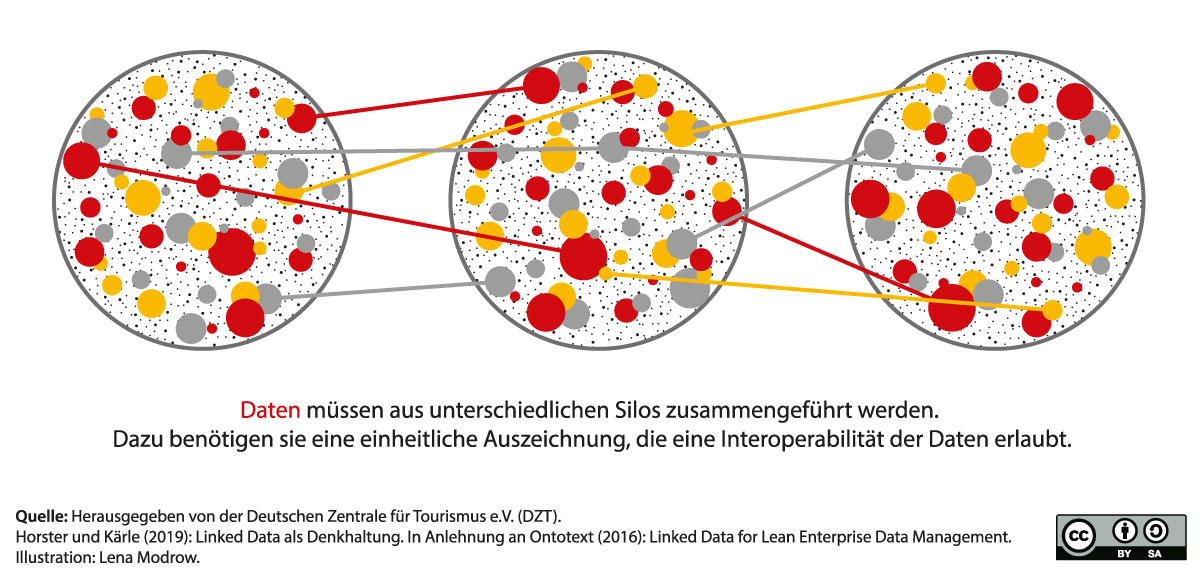
Daten können sehr heterogen strukturiert sein und sind es in der Regel im Deutschlandtourismus auch. Maschinen können diese Unterschiede nicht ohne weiteres entschlüsseln. Sollen Daten also auch für Maschinen aufbereitet werden, so ist hierfür eine einheitliche Auszeichnung der Daten die Voraussetzung: Jeder Radweg müsste auf dieselbe Art beschrieben werden.
Dann wäre die Auszeichnungslogik unmittelbar verständlich und die Angaben von unterschiedlichen Radwegen können aus verschiedenen Datenquellen (Datensilos) kombiniert werden.
Diese Idee der einheitlichen Beschreibung der Datenstruktur und deren anschließende Verbindung nennt sich Linked Data. Tim Berners-Lee hat diese Weiterentwicklung des Web sehr anschaulich in einem TED-Vortrag erläutert, der bis heute wegweisend ist:
Mittels Linked Data können also Informationen aus unterschiedlichen Kontexten kombiniert werden. Beschreibungen von Radtouren müssten nicht mehr an verwaltungspolitischen Grenzen enden, sondern könnten über eine einheitliche Struktur der Daten für den Gast fortgeführt werden.
Linked Data ist der Schlüssel
Aktuell gibt es bei der Aufbereitung von Daten auch im Tourismus noch eine starke Orientierung am Menschen. Wenn Informationen über einen Radweg abgelegt werden, dann erfolgt dies meist mit dem Ziel, diese in einer bestimmten App oder auf einer Website für die eigenen Gäste zu veröffentlichen. Dagegen ist prinzipiell auch nichts einzuwenden.
Allerdings wird es künftig immer wichtiger werden, Daten so bereitzustellen, dass sie außerhalb von einem spezifischen Anwendungsfall universell eingesetzt werden können. Hierzu ist es wichtig, dass sie mithilfe einer Ontologie einheitlich beschrieben sind. Im Tourismus sind dies schema.org sowie ein erweitertes Vokabular. Letzteres wird aktuell von einer Arbeitsgemeinschaft (DACH-KG) speziell für den Tourismus entwickelt.
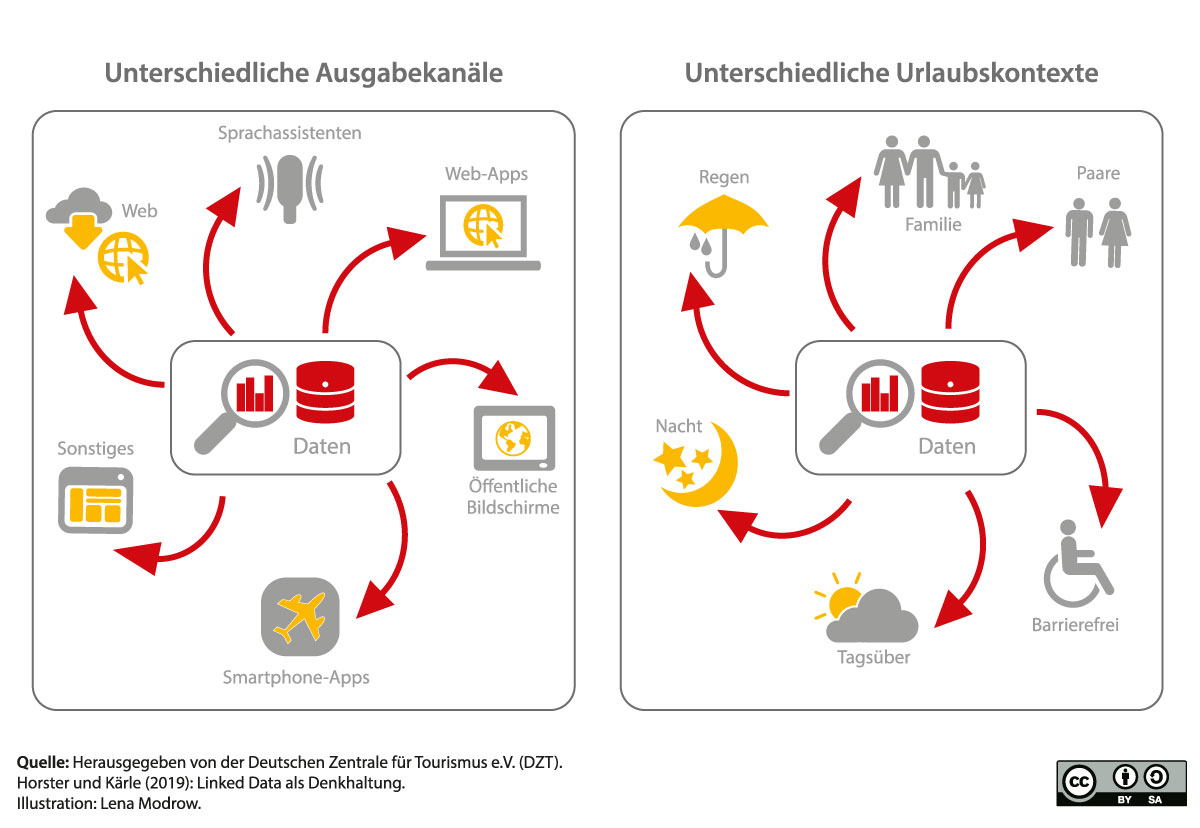
Es wird von einer „Interoperabilität“ gesprochen: Daten können unabhängig vom Ausgabekanal und auch unabhängig vom Kontext von Menschen und Maschinen weiterverarbeitet werden. Dies hat zwei primäre Hintergründe:
Datenmanagement als Zukunftsaufgabe
Das Web entwickelt sich durch die unterschiedlichen Anforderungen immer mehr von einem Netz aus verknüpften Dokumenten hin zu einem Netz aus verknüpften Datensätzen.
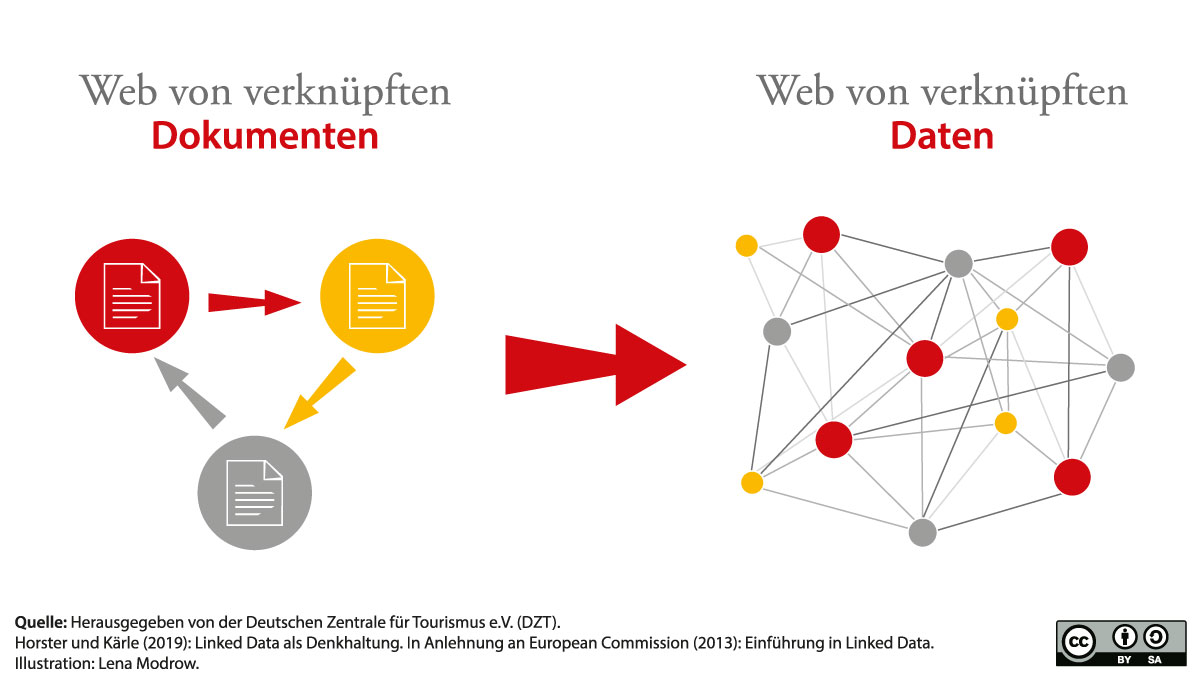
Diese Anpassung des Datenmanagements ist vor dem Hintergrund der Entwicklung des Internet der Dinge höchst relevant: Mittels Sensorik werden künftig sehr viele Kontextdaten zu Wetter, Zeit, Zuständen (leer oder voll, hell oder dunkel usw.) zur Verfügung stehen. In Verbindung mit strukturiert aufgearbeiteten Daten zu touristischen POIs, Events usw. können hier vielfältige Anwendungen entstehen. Die Vision geht hier oft in Richtung automatische Dienste, die je nach Urlaubskontext (Regen oder Sonne, morgens oder abends, Hoch- oder Nebensaison usw.) Empfehlungen aussprechen, die sowohl zur Situation als auch zum jeweiligen Gast passen.
Spätestens jetzt wird deutlich, dass ein modernes Datenmanagement eine zentrale Zukunftsaufgabe der DMO sein kann. Konkret bedeutet dies, dass der Fokus des Datenmanagements auf der Lesbarkeit, Interpretierbarkeit und Nutzbarkeit von Daten für Maschinen (und Menschen) liegen sollte.

Eric Horster
Fachhochschule Westküste
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: www.eric-horster.de

Elias Kärle
Universität Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/