A mirror of (tourist) reality.
Data management today and tomorrow.
In connection with Linked Open Data, the keyword Knowledge Graph is often mentioned. It is often not entirely clear what is meant by the term. A Knowledge Graph is, in short and generalized terms, a graph database that fulfills certain criteria (see infobox).
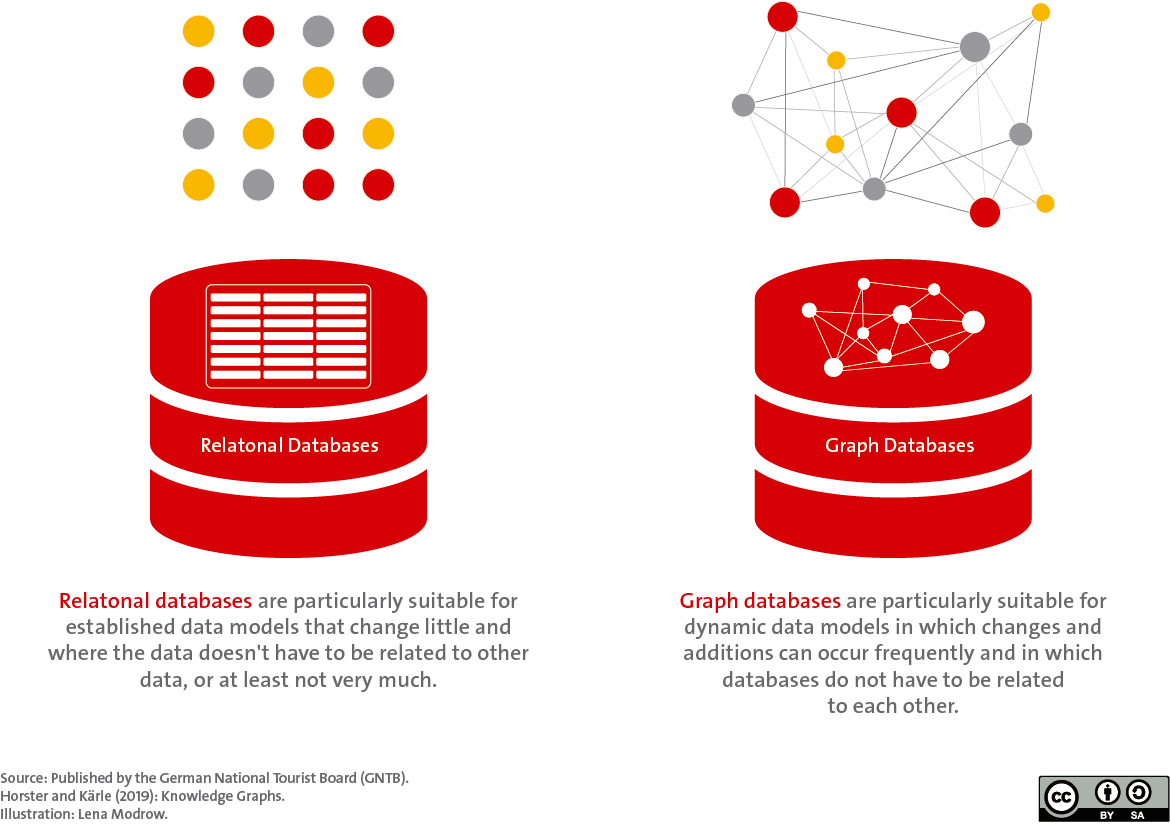
A good starting point to explain what a graph database is, is to compare it with a relational database. Relational databases store information about trails, hotels, events, POIs or other tourism-related data in tables with rows and columns. The type of data storage in relational databases is thus comparable to a subway timetable with the departure times of the respective stops.
Orientation is limited to the tabular timetable and the tram network is difficult to identify even if all stop maps were available. The route network and interchanges are much easier to grasp via a visualization in network structure.
Similarly, the distinction between relational databases and graph databases is similar: a graph specializes in networking data. A relational database can also do this in principle, but queries across multiple tables require much more effort and are sometimes only possible via complicated detours. In a complex world, however, the relationship between data is increasingly important, which is why relational databases can reach their limits.
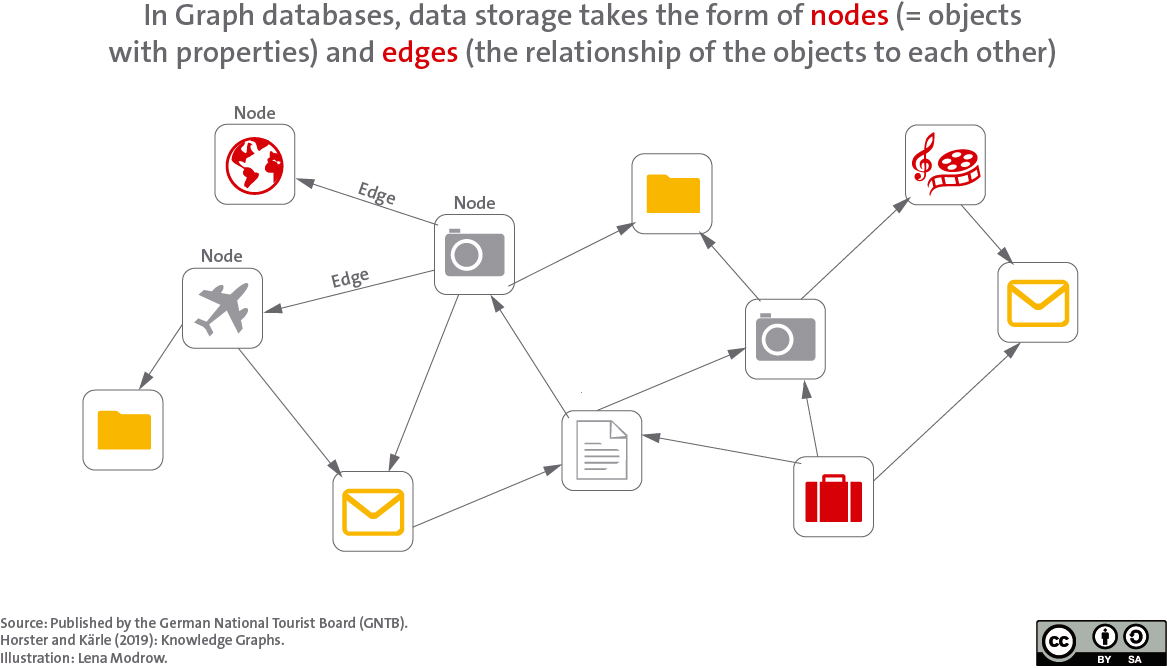
The properties of the lines defined in the tables of relational databases (for instance altitude, degree of difficulty, etc. for hiking trails) can only be changed or added with difficulty. Graph databases work differently here: there is no predefined data model. Each data set is rather represented in so-called nodes and the relationship of the data to each other is visualized by means of connections (the edges). When new connections are added, the data model can be extended (see figure).
Another advantage is that graph databases can process complex queries in a short time due to this form of data storage.
Preparing data management for AI applications
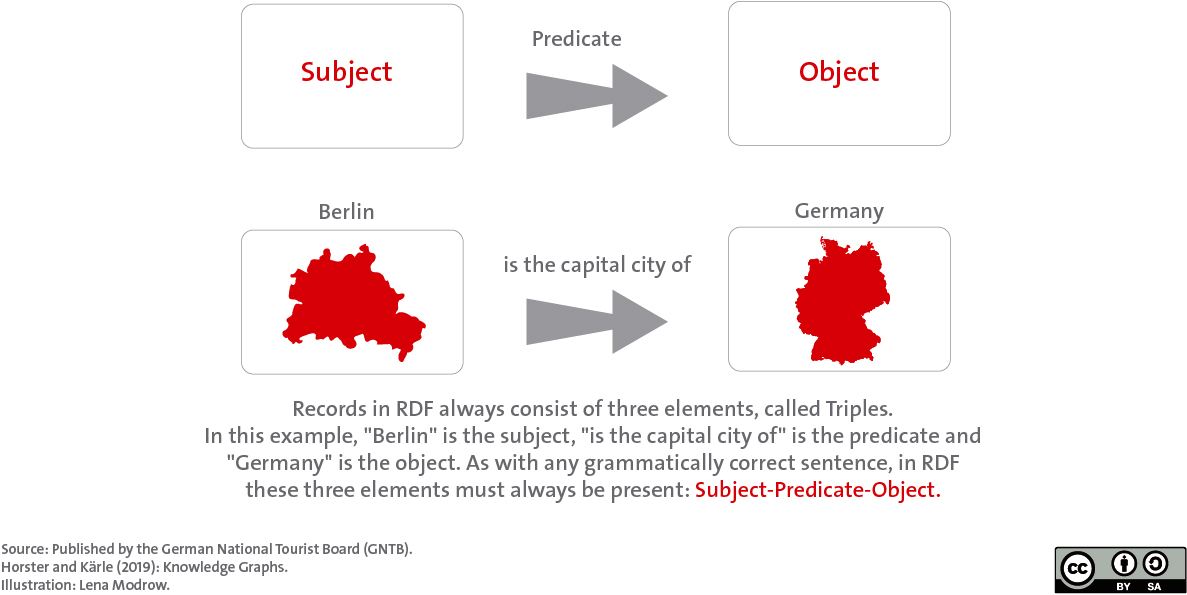
Data is related to each other via the network structure of data storage using RDF. Since the data is uniformly identified in the network, interfaces become obsolete. If the Knowledge Graph is also open, the data can be used by everyone and applications no longer lie behind the paywalls of large players who only allow the expansion of the range of functions of digital services against payment.
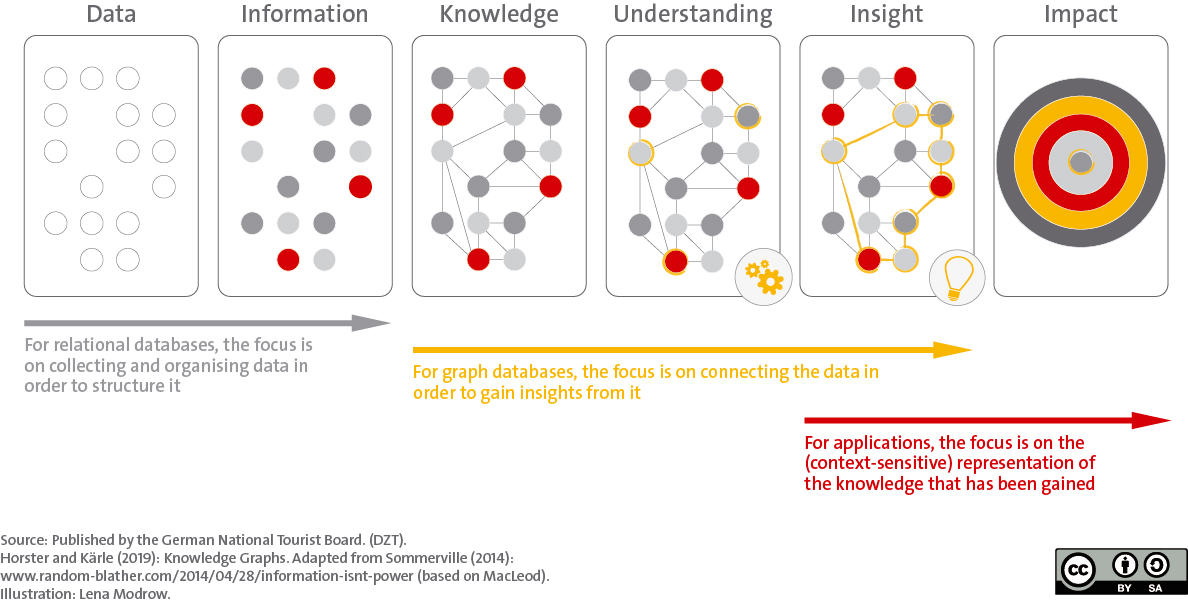
If data is available individually in digital form, then a meaning can be attributed to it via an ontology (markup language). This turns data into information, as individual data regarding a hotel, restaurant, etc. can be displayed in aggregated form. Information becomes knowledge when the information is related to each other. For example, if the geodata of a hotel is set in relation to a hiking trail, then travellers know where they can plan an overnight stay. Guests can understand data about applications because queries can be used to contextually evaluate the relationship of the data and present it in an interface. Thus, guests gain knowledge about different holiday situations and can classify them accordingly, which can lead to a change in behaviour(impact).
For data management, this means that data stored in relational databases can be semantically tagged using an ontology such as schema.org and then stored (in parallel) in a graph database. Graph databases then represent the individual pieces of information in a network using RDF. Applications can then be used by guests to access these data networks (see figure).
Complementary database systems
Relational databases and a parallel Knowledge Graph, which describes the relationship between the data, are not mutually exclusive. Rather, these systems can be viewed as complementary . If such a Knowledge Graph can be established in tourism, as is currently being developed by the GNTB, this will be an important step towards linking data at state and regional level.
At the DMO level, this means first and foremost that there must be agreement on the markup language (ontology) and that the data must be open, complete and up-to-date. The GNTB also prefers schema.org because this ontology represents a de facto standard and is therefore compatible with other (non-tourist) data. RDF query languages such as SPARQL (which can be programmed to search and extract the dataset) can be used to search and extract administrative data, in order to display all public toilets in a location and correlate them with data on walking routes for instance. The conceivable scenarios here are manifold and can lead to special tours, in which all public apple trees can be explored in order to always have a snack ready on the way.
Therefore, it can be stated that graph databases are a modern form of data management, which offer a wide range of possibilities for the development of digital services.

Eric Horster
West Coast University of Applied Sciences
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: http://eric-horster.de/

Elias Kärle
University of Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/