Ein Spiegel der (touristischen) Wirklichkeit.
Datenmanagement heute und morgen.
Im Zusammenhang mit Linked Open Data fällt häufig das Stichwort Knowledge Graph. Dabei ist oftmals nicht ganz klar, was mit dem Begriff gemeint ist. Ein Knowledge Graph ist verkürzt und verallgemeinert gesprochen eine Graphdatenbank, welche bestimmte Kriterien erfüllt (siehe Infobox).
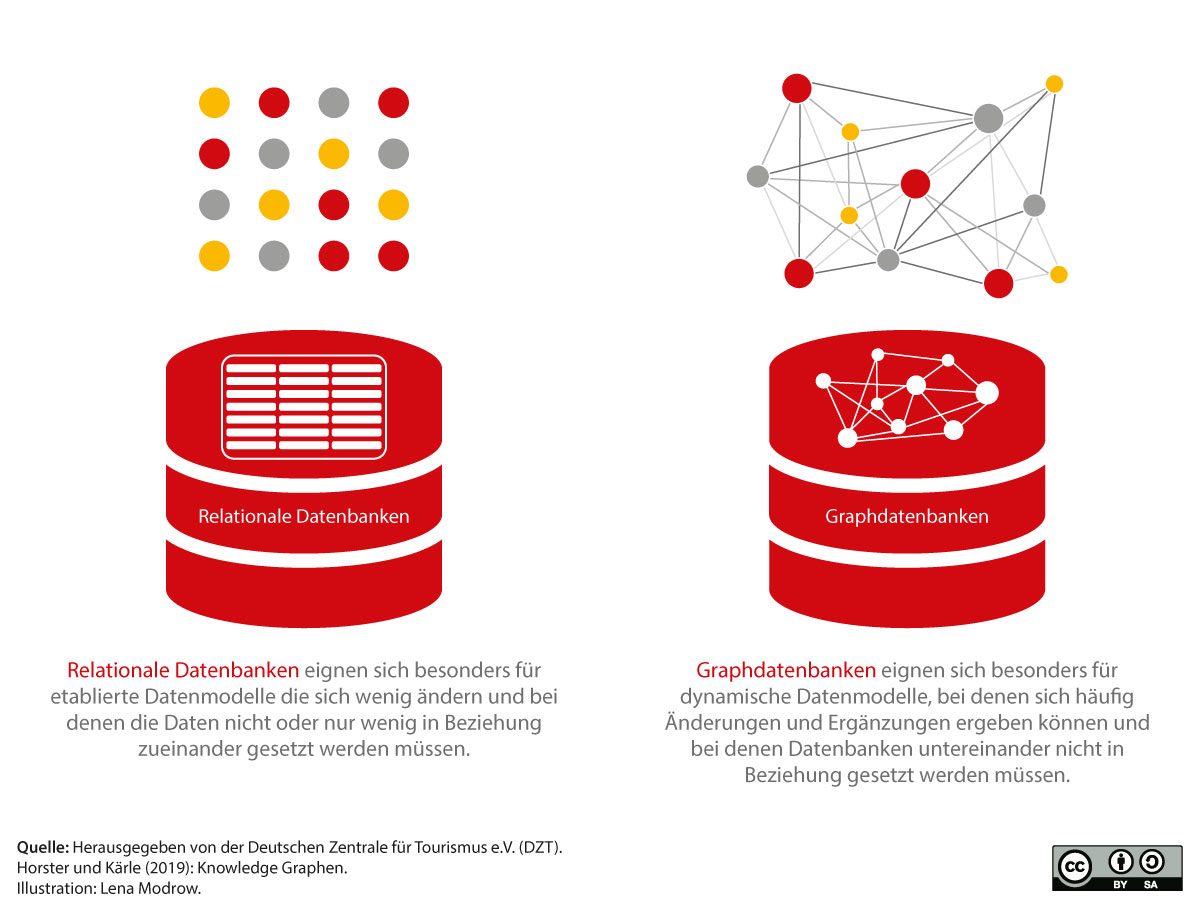
Ein guter Ausgangspunkt zur Erklärung, was eine Graphdatenbank ist, ist der Vergleich mit einer relationalen Datenbank. Relationale Datenbanken speichern Angaben zu Wanderwegen, Hotels, Events, POIs oder anderen touristisch relevanten Daten in Tabellen mit Zeilen und Spalten. Die Art der Datenablage bei relationalen Datenbanken ist damit vergleichbar mit einem U-Bahnfahrplan auf dem die Abfahrtszeiten der jeweiligen Haltestelle stehen.
Die Orientierung ist dabei auf den tabellarischen Fahrplan beschränkt und das Straßenbahnnetz lässt sich selbst dann nur schwer erkennen, wenn alle Haltestellenpläne zur Verfügung stünden. Das Streckennetz und Umsteigemöglichkeiten sind sehr viel besser über eine Visualisierung in Netzwerkstruktur zu erfassen.
Ähnlich verhält es sich bei der Unterscheidung zwischen relationalen Datenbanken und Graphdatenbanken: Ein Graph ist auf die Vernetzung von Daten spezialisiert. Eine relationale Datenbank kann dies prinzipiell auch, jedoch erfordern Abfragen über mehrere Tabellen hinweg sehr viel mehr Aufwand und sind zum Teil nur über komplizierte Umwege möglich. In einer komplexen Welt ist die Beziehung der Daten zueinander jedoch zunehmend wichtiger, weshalb relationale Datenbanken an ihre Grenzen stoßen können.
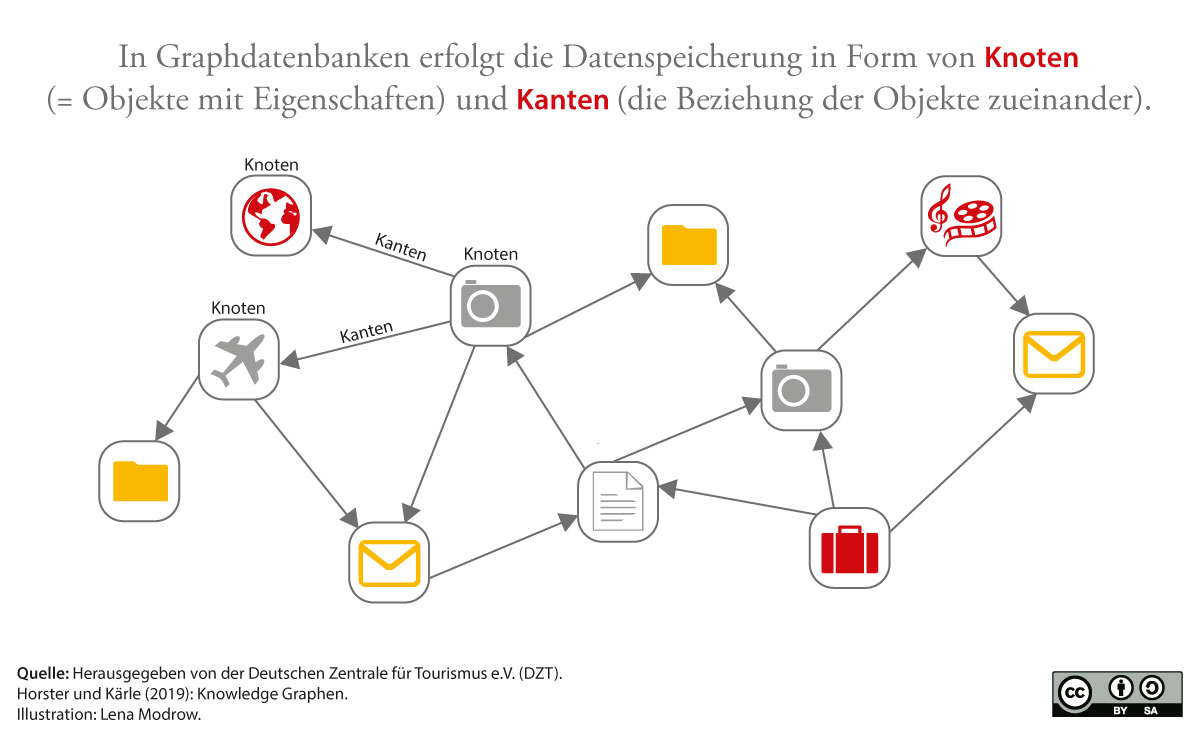
Die bei relationalen Datenbanken in den Tabellen definierten Eigenschaften der Zeilen (bei Wanderwegen bspw. Höhenmeter, Schwierigkeitsgrad usw.) können später nur schwer geändert oder ergänzt werden. Graphdatenbanken arbeiten hier anders: Es gibt kein vorgegebenes Datenmodell. Vielmehr ist jeder Datensatz in sogenannten Knoten dargestellt und die Beziehung der Daten zueinander ist mit Verbindungen (den Kanten) visualisiert. Wenn neue Verbindungen hinzu kommen, kann das Datenmodell erweitert werden (siehe Abbildung).
Ein weiterer Vorteil ist, dass Graphdatenbanken durch diese Form der Datenablage komplexe Abfragen in geringer Zeit bearbeiten können.
Das Datenmanagement auf KI-Anwendungen vorbereiten
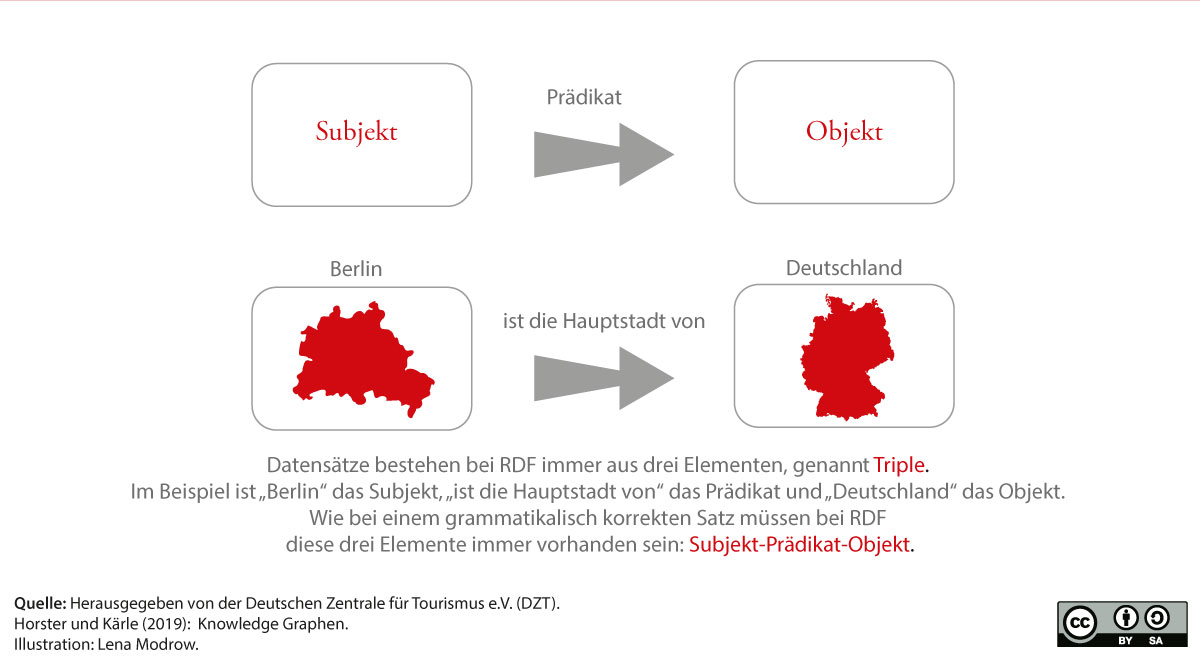
Über die Netzwerkstruktur der Datenhaltung mittels RDF werden Daten zueinander in Beziehung gesetzt. Dadurch, dass die Daten einheitlich im Netzwerk ausgezeichnet sind, werden Schnittstellen obsolet. Wenn der Knowledge Graph noch dazu offen ist, können die Daten von allen genutzt werden und Anwendungen liegen nicht mehr hinter den Paywalls von großen Playern, die eine Ausweitung des Funktionsumfangs digitaler Dienste nur gegen Bezahlung ermöglichen.

Wenn Daten einzeln digital vorliegen, dann kann diesen über eine Ontologie (Auszeichnungssprache) eine Bedeutung zugeschrieben werden. Darüber wird aus Daten eine Information, da Einzeldaten zu einem Hotel, einem Restaurant usw. aggregiert dargestellt werden können. Information wird dann zu Wissen, wenn die Informationen zu einander in Beziehung gesetzt werden. Wenn bspw. die Geodaten von einem Hotel in Beziehung zu einem Wanderweg gesetzt werden, dann wissen Reisende, wo sie eine Übernachtung einplanen können. Gäste können Daten über Anwendungen verstehen, da über Abfragen die Beziehung der Daten kontextuell ausgewertet und in einem Interface dargestellt werden können. Darüber gewinnen Gäste Erkenntnisse über verschiedene Urlaubssituationen und können diese entsprechend einordnen, was zu einer Verhaltensänderung führen kann (Auswirkung).
Für das Datenmanagement bedeutet dies konkret, dass Daten die in relationalen Datenbanken gespeichert sind mittels einer Ontologie wie schema.org semantisch ausgezeichnet und dann (parallel) in einer Graphdatenbank abgelegt werden können. Durch Graphdatenbanken werden die Einzelinformationen dann mittels RDF in einem Netzwerk dargestellt. Über Anwendungen kann auf diese Datennetzwerke auf Seiten der Gäste zurückgegriffen werden (siehe Abbildung).
Komplementäre Datenbanksysteme
Relationale Datenbanken und ein parallel betriebener Knowledge Graph, welcher die Beziehung der Daten zueinander beschreibt, schließen einander nicht aus. Vielmehr können diese Systeme komplementär betrachtet werden. Wenn im Tourismus ein solcher Knowledge Graph, wie er aktuell von der DZT entwickelt wird, etabliert werden kann, ist dies ein wichtiger Schritt, um Daten auf Ebene der Bundesländer und Regionen miteinander zu verbinden.
Auf Ebene der DMOen bedeutet dies in erster Linie, dass Einigkeit bei der Auszeichnungssprache (Ontologie) herrschen muss und dass die Daten offen, vollständig und aktuell sind. Hier wird seitens der DZT auch deshalb schema.org präferiert, weil diese Ontologie ein de-facto Standard darstellt und damit auch mit anderen (nicht touristischen) Daten kompatibel ist. So können über RDF-Abfragesprachen wie SPARQL (durch entsprechende Programmierung kann der Datenbestand durchsucht und extrahiert werden) auch Verwaltungsdaten durchsucht und genutzt, um bspw. alle öffentlichen Toiletten in einem Ort anzuzeigen und mit Daten zu Wanderrouten in Beziehung zu setzen. Die denkbaren Szenarien sind hier mannigfaltig und können bis hin zu speziellen Touren führen, bei denen alle öffentlichen Apfelbäume erkundet werden können, um unterwegs stets einen Snack parat zu haben.
Es kann daher festgehalten werden, dass Graphdatenbanken eine moderne Form der Datenhaltung sind, welche vielfältige Möglichkeiten für die Entwicklung digitaler Serviceleistungen bieten.

Eric Horster
Fachhochschule Westküste
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: www.eric-horster.de

Elias Kärle
Universität Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/