Datenmanagement modular denken.
Die Evolution des Web.
Das World Wide Web befindet sich in einem Transformationsprozess. Aktuell entwickelt sich das semantische Web, auch Web 3.0 genannt, bei dem die Maschinenlesbarkeit von Daten im Fokus steht. Ziel ist es, dass Maschinen Sinnzusammenhänge eigenständig herstellen. So können Fragen von Nutzern unmittelbar beantwortet werden. Diese Entwicklungen ändern schon jetzt das Informationsverhalten von Reisenden.
Es ist abzusehen, dass Datenbestände künftig von Maschinen nicht nur dargestellt, sondern auch verstanden und interpretiert werden müssen: Gäste stellen spezifische Fragen und die Antworten dazu werden an den jeweilige Ausgabekanal angepasst und ausgegeben.
Das bedeutet, dass identische Informationen entsprechend dem Anbieter und Ausgabegerät des Gastes und seiner jeweiligen Urlaubssituation unterschiedlich dargestellt werden – idealerweise in Echtzeit.
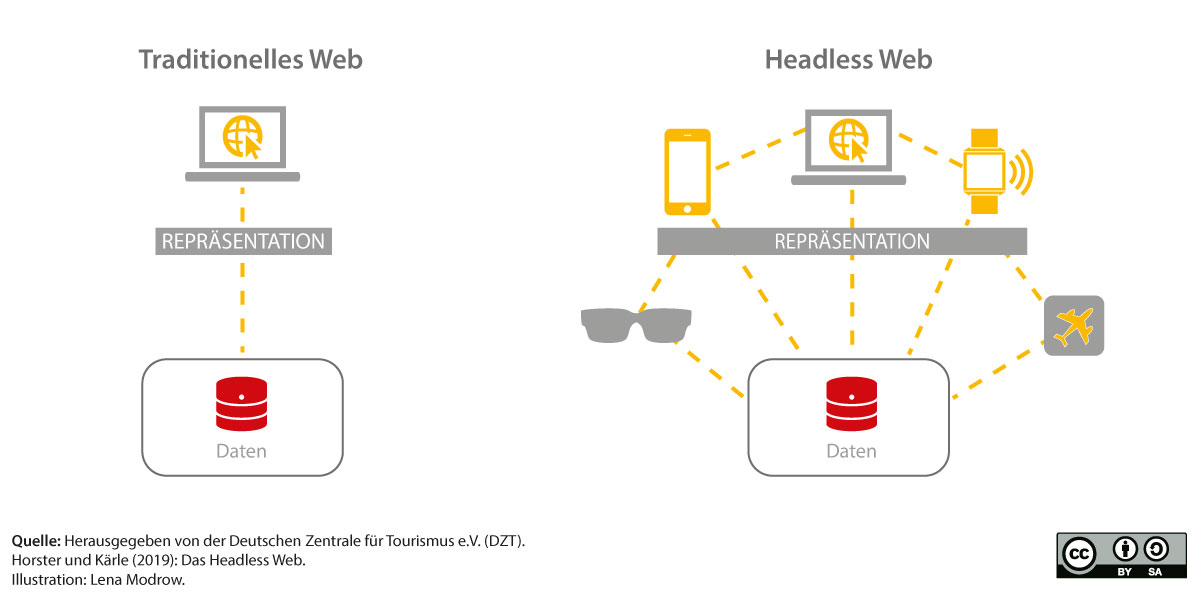
Die grundlegende Veränderung dieser Form der Datenverarbeitung wird auch als „Headless Web“ bezeichnet. Bei dieser Metapher sind die Daten der Körper und die Repräsentation der Kopf. „Headless“ bedeutet nun, dass der Körper (also die Daten) bestehen bleiben. Der Kopf – also die Repräsentation der Daten – wird nicht mehr vom Ersteller der Inhalte selbst bestimmt, da die Ausgabe auf unterschiedlichen Kanälen und Plattformen erfolgen kann.
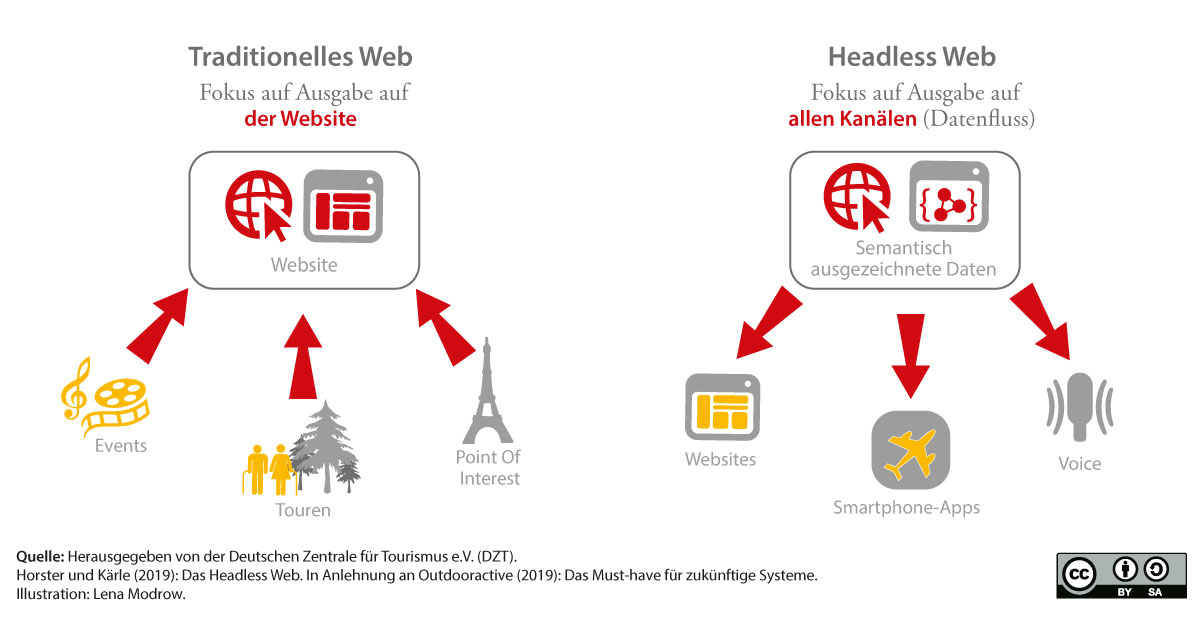
In der „alten“ Logik des Web werden Daten in eine Datenbank gespielt und dann an einem Ort (in der Regel die eigene Website) ausgespielt. In der neuen Logik des Web müssen Daten nicht mehr zwingend grafisch auf einer Website dargestellt werden.
Wichtig ist, dass sie für Maschinen les- und interpretierbar sind, damit sie mit anderen kombiniert und auf unterschiedlichsten Ausgabekanälen dargestellt werden können. Hierzu müssen Daten eine einheitliche semantische Auszeichnung erhalten, damit sie „interoperabel“ sind (siehe Abbildung).
Was bedeutet das für touristische Akteure?
Das klassische Webdesign wird zunehmend in den Hintergrund rücken. Vielmehr ist die Datenarchitektur entscheidend: Die Daten müssen korrekt, vollständig, aktuell und nach einer gängigen Ontologie (einer Auszeichnungssprache wie bspw. schema.org) beschrieben werden.
Eine Ausgabe der Daten wäre somit auch vor Ort möglich: So könnten die Informationen zu Restaurants aus den Websites der jeweiligen Gastronomiebetriebe extrahiert und auf digitalen Anzeigetafeln im Urlaubsort ausgespielt werden. Den Besuchern würde dann nur das Gastronomieangebot angezeigt, welches tatsächlich geöffnet ist.
Die Gäste müssten dazu weder die Websites der Restaurants durchsuchen noch eine Suchmaschine befragen.
Jenseits der Walled Gardens
Große Player wie Google sind aktuell (noch) die Treiber des Headless Web. Der Knowledge Graph von Google macht das deutlich: Es werden Antworten auf Fragen gegeben – ohne dabei den Umweg über die Website desjenigen zu nehmen, der die Informationen anbietet. Bei einer Suche nach bspw. regionalen Unternehmen wie Restaurants oder Veranstaltungsstätten, erhalten die Nutzer zunehmend eine Übersicht direkt auf der Suchergebnisseite.
Auch bei News, Rezepten oder Personen extrahiert Google diese Informationen schon direkt und zeigt diese auf das jeweilige Ausgabemedium angepasst an. Erst darunter werden dann die Websites, auf denen die Informationen stehen, gelistet. Bei Sprachassistenten ist es ähnlich. Auch hier werden Antworten präferiert direkt vorgelesen anstatt auf eine Website zu verweisen, die der Nutzer dann selbst durchsuchen und durchlesen müsste. Informationen, die von Sprachassistenten ausgegeben werden haben dabei kein grafisches, sondern ein auditives Interface.
Große Plattformen bauen nun zunehmend eigene digitale Ökosysteme auf, was die Aufmerksamkeit bei einem Anbieter bündelt (auch Ökonomie der Aufmerksamkeit genannt) und zu einer Art Web-im-Web führt. Alle Informationen sind innerhalb der Plattform auffindbar, sodass diese nicht mehr verlassen werden muss. In diesem Zusammenhang spricht man von einem „Walled Garden“, also ein umschlossener Garten bzw. eine geschlossene Plattform, in der Hardware- und/oder Softwarekomponenten (Betriebssysteme, Apps) auf ein System beschränkt sind.

In Summe bedeuten diese Entwicklungen, dass Informationen zunehmend direkt auf den Plattformen ausgegeben werden. Je nachdem, wer die Informationen mit welchem Medium extrahiert, erfolgt anschließend eine andere Form der Ausgabe. Auf Kundenseite ist der Vorteil offensichtlich: Sie finden alles an einem Ort und auch einheitlich aufbereitet. Für touristische Akteure wie Hotelanbieter oder Restaurants ist dies aber problematisch.
Sie werden im digitalen Raum zunehmend unsichtbar und die eigene Unternehmenswebseite verliert immer mehr an Relevanz. Durch diese Entwicklungen haben es kleine touristische Betriebe zusehends schwer, die Sichtbarkeit ihrer eigenen Website im Netz zu sichern.
Ein Internet ohne derartige „Walled Gardens“ würde hier viele Vorteile bringen. Wenn Daten offen und semantisch ausgezeichnet auf Websites bereitgestellt werden, dann sind sie nicht auf nur eine Plattform beschränkt, sondern könnten allen zur Verfügung gestellt werden.
It’s all on the Website!
Damit die Sichtbarkeit auf Plattformen wie Google oder Facebook auch für lokale (touristische) Unternehmen bestehen bleibt, müssen sie möglichst umfassende Angaben in den „virtuellen Orten“ der Plattformbetreiber wie Google My Business oder Facebook Places usw. hinterlegen.
Wenn diese Daten also ohnehin für diese Plattformen aufgearbeitet werden müssen, können sie im gleichen Zuge auch für alle anderen Akteure im Web bereitgestellt werden. Damit sie aber von anderen genutzt werden können, sollten sie mit einem de-facto Standard wie schema.org semantisch ausgezeichnet werden und als solches auf der eigenen Website bereitgestellt werden.

Die Informationen sollten dabei nicht auf Unternehmensangaben beschränkt bleiben. Auch Veranstaltungen, POIs, Wanderrouten, Verfügbarkeiten, Preise oder Rezepte können maschinenlesbar auf der eigenen Website veröffentlicht und so von allen genutzt werden. Ein gängiges Format, um all diese Daten bereitzustellen, ist JSON-LD. Damit touristische Akteure darin unterstützt werden, die Daten in diesem Format auszugeben, gibt es Generatoren, welche die gewünschten Angaben automatisch mit schema.org beschreiben und in einem Code Snippet (ein kleiner und automatisch generierter Programmcode) im gewünschten Ausgabeformat bereitstellen, das dann einfach auf der Website eingefügt werden kann.
Darüberhinaus hilft diese strukturierte Auszeichnung der Daten auch bei der Sichtbarkeit innerhalb der großen Suchmaschinenanbieter, da sie prominent in der Suchergebnisseite angezeigt werden können. Dies gilt zumindest für diejenigen Datentypen, die in der Google Search Gallery aufgelistet sind. Touristisch relevant sind hier bspw. Angaben zu Unternehmensangaben von lokalen Akteuren (Restaurants, Hotels, Freizeitanbieter usw.), Veranstaltungen oder Rezensionen.

Eric Horster
Fachhochschule Westküste
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: www.eric-horster.de

Elias Kärle
Universität Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/