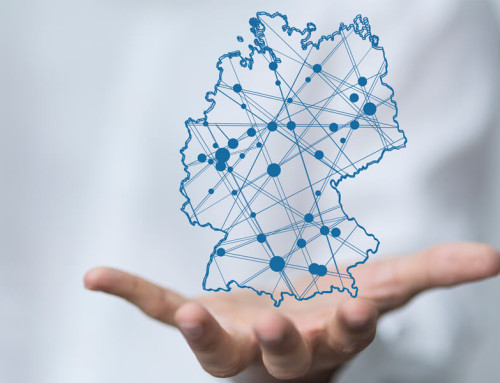
A Knowledge Graph as a modern form of data architecture.
In the future, guests will increasingly search for information on the basis of natural language. Search requests based on natural language are dictated to the smartphone or requested in the form of questions to digital assistants such as Google Assistant or Alexa from Amazon. It should be noted that queries as well as the expected responses of natural language input are different from a classic search query. Complexity increases because requests are often made in a specific context and depend on weather, current location, personal preferences, etc. Thus, when asked “What can I do in city X on the weekend?”, the natural language should be decoded and a concrete personalized answer should be given, taking into account the particular situation of the guests. For this purpose, it is necessary that different data are related to each other: Tours with gastronomy offers, gastronomy with events, events with mobility options, etc.
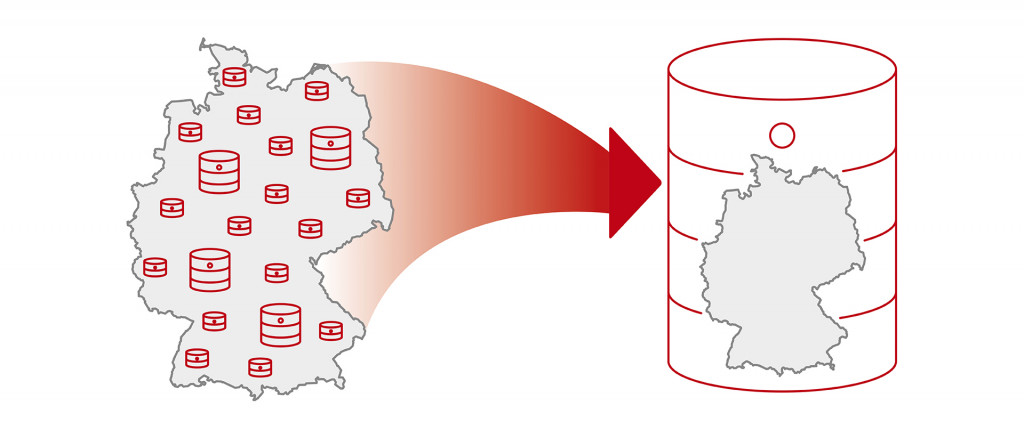
The aim is to consolidate the distibuted and heterogeneous data stock in a central and open Knowledge Graph for German tourism, which can be used jointly by tourism stakeholders and external service providers.
Graph databases are pivotal for providing such situationally appropriate answers for guests. Due to the data architecture in the form of a network, individual data points can be very well related to each other. Just as in the real world public transport, event locations, attractions (POI) or restaurants in a city are related to each other, these connections can also be represented in a graph database. There is no need to reprogram every relationship, because in graph databases relationships already result from a clean data entry, where the relationships are explicitly defined. In addition, newly entered data can be linked to already stored data, for example by geo-referencing them (so-called geo-reasoning).
Relationships between data can be mapped very well via graph databases.
In order to achieve such functionality, the data must offer an appropriate quality and be related to each other in such a Knowledge Graph. Additional information such as geo-coordinates are necessary in order to establish the connection from an excursion destination to the nearest restaurant. This means that accuracy in data maintenance is becoming increasingly important. The aim is to connect the distributed and heterogeneous tourism data available in Germany via a knowledge graph.
Graph Databases in Distinction to Relational Databases
The term database is often associated with tables inlcuding many columns and rows that resemble an Excel spreadsheet. Such databases are also called relational because the individual tables can be linked to each other via relations. This makes it possible, for example, to define a connection between a point of interest (POI) and nearby restaurants. Such relationships can be developed in relational databases. However, the tables are stiff and can only be changed with difficulty. In addition, a large number of multi-level relationships that are created by linking tables can quickly lead to confusion.
Graph databases differ from relational databases in their structure and design. They are created in a network structure. Nodes (visually represented as points) are connected by edges (represented as lines). The possible connections in this network structure are much more flexible than in a relational database. Data and their relationship to each other can be adapted and exchanged, allowing flexible changes and extensions.

The DMO’s various databases are to be standardised and made centrally available to all.
At present, tourism data is largely stored in relational databases, where it is stored in individual tables that are rarely interrelated. The aim is to process this data so that it is available in a consistent way, so that inputs from different DMOs can be linked. The relationship of data with each other can basically be established in relational databases through connections. However, this quickly becomes confusing, as requests on several levels can become very complex. Graph databases, on the other hand, are designed to map the relationship of data to each other. Data architecture in network structures is becoming increasingly important because coherent described data and their relationship to each other can be automatically understood and further processed by machines, which is an important support for AI applications. Startups can also decipher this form of data storage very easily, allowing them to directly access the dataset and implement innovative ideas without having to spend time laboriously deciphering the logic of how the data relates to each other. Therefore, a central graph database for German tourism is to be developed.
Google, among others, operates such a graph database, which the company calls “Knowledge Graph” because the goal is to provide context-sensitive answers by leveraging diverse data sources. Google can, for example, display suitable gastronomic offers or events along a hiking trail. Access to this network structure of data can also be used to generate better responses for voice assistants. The disadvantage of this Knowledge Graph from Google: It is not openly accessible and is only used by Google for its own digital applications. Thus, it is not possible to fall back on already existing links within the Google universe.
Advantages of a Knowledge Graph for German Tourism
Therefore, an open and independent Knowledge Graph for German tourism is to be established. Tourism stakeholders benefit from the provision of data in such a Knowledge Graph by linking it to other data. For example, based on geodata, information about nearby restaurants on hiking or biking routes can be put out and many other relationships between various data can be established. This will establish a supra-regional network in the Knowledge Graph of German tourism, as the tourism data of all participating players will be uniformly labelled and integrated. This makes it possible to link data nationwide, which is interesting, for example, when tours extend across several federal states.
On this basis, real and cross-regional cooperations can emerge, through which new digital services for guests can be developed. These extensive possibilities for using the data also support preparation for applications based on artificial intelligence. This is because the uniform description of the data using an established ontology such as schema.org and its storage in a network structure makes both the data itself and its relationships to one another machine-readable. You do not necessarily have to develop your own applications for this. The data contained in the Knowledge Graph of German tourism can also be used by Google as well as by other external players such as mobility providers, etc. The aim is to achieve maximum visibility through this.
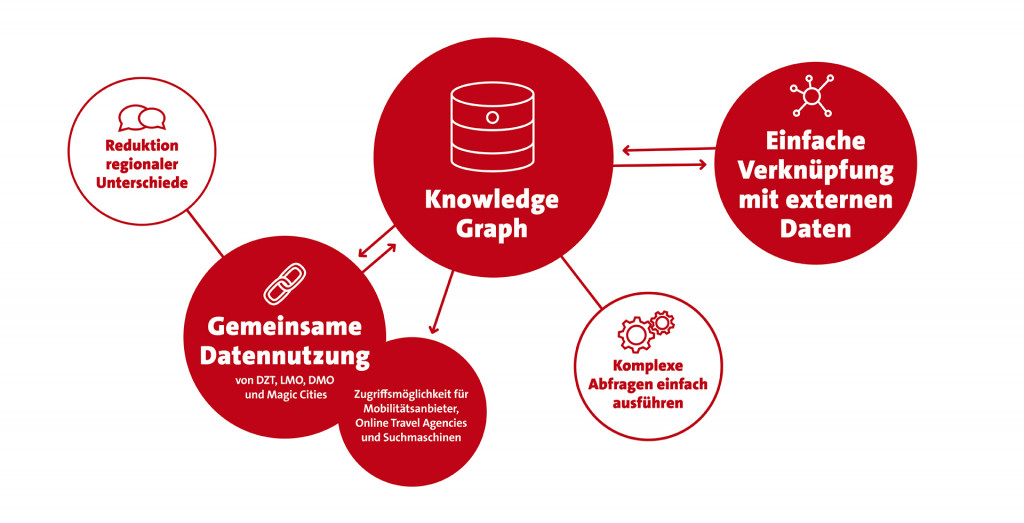
The Knowledge Graph as the Data Architecture of the Future
Artificial intelligence (AI) applications often still seem like science fiction. But they will be standard sooner than some people think possible today. It is therefore important to provide the data basis for this now. The Knowledge Graph plays an essential role for German tourism. Because artificial intelligence is not comparable to human intelligence in several ways. This specifically means:
The answers and predictions provided by the above examples can be extracted from a Knowledge Graph very well. This is because graph databases can use queries to independently create meaningful links (e.g., based on geographic location) and adjust them based on experience. If guests accept certain offers, the system can adjust itself more and more refined thanks to this feedback and make even better suggestions. However, before machines can work autonomously, they need a good database. The data should therefore be consistently labelled on the one hand and be available in a network structure on the other. If this is the case, they can be queried via algorithms in every conceivable direction. For this reason, the technical implementation of the Knowledge Graph for German tourism must always be seen in connection with the establishment of a common data standard.
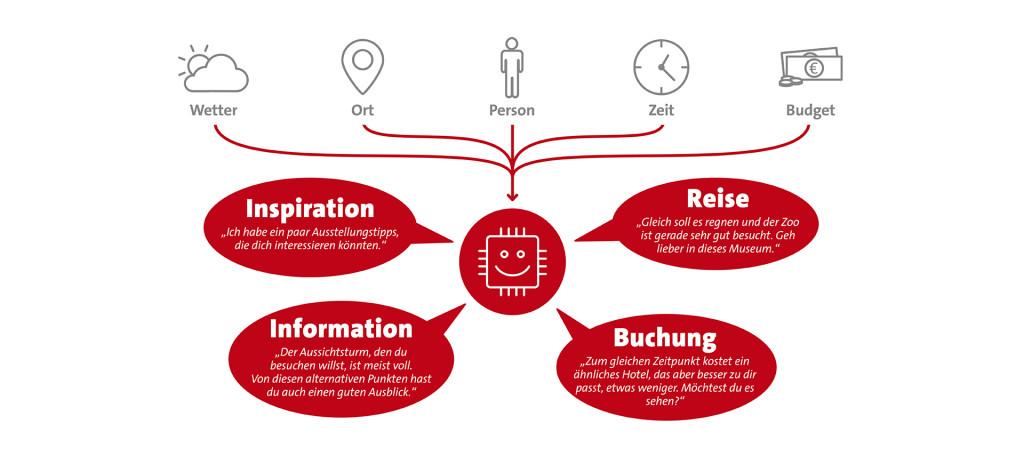
The data in a Knowledge Graph helps to provide automated personalized recommendations to guests.
Autonomous Recommender pursue the goal to support tourists, at the same time there is the possibility to influence them in their behaviour. In this way, predictions (predictive analytics) and personal recommendations derived from them can be provided both as a digital service for guests at the destination and as an instrument for visitor guidance.
The basis for real-time recommendations can be the Knowledge Graph database for German tourism. Its functions can be combined into an autonomous recommender as a holiday companion.

Eric Horster
West Coast University of Applied Sciences
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: http://eric-horster.de/

Elias Kärle
University of Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/