Ein Knowledge Graph als moderne Form der Datenarchitektur.
Gäste werden künftig zunehmend auch sprachbasiert nach Informationen suchen. Die Sprachanfragen werden also mittels Diktierfunktion auf dem Smartphone eingesprochen oder in Form von Fragen an digitale Assistenten wie den Google Assistant oder Alexa von Amazon gerichtet. Bei der Spracheingabe ist zu beachten, dass sich die Anfragen und auch die erwarteten Antworten von einer klassischen Suchanfrage unterscheiden. Die Komplexität steigt, weil Anfragen oftmals in einem spezifischen Kontext und in Abhängigkeit von Wetter, derzeitigem Aufenthaltsort, persönlichen Präferenzen usw. gestellt werden. Bei der Frage „Was kann ich am Wochenende in Stadt X unternehmen?“ sollte somit die natürliche Sprache entschlüsselt und eine konkrete personalisierte Antwort gegeben werden, welche die jeweilige Situation der Gäste mit einbezieht. Hierzu ist es erforderlich, dass unterschiedliche Daten miteinander in Beziehung gesetzt werden: Touren mit Gastronomieangeboten, Gastronomie mit Veranstaltungen, Veranstaltungen mit Mobilitätsoptionen usw.
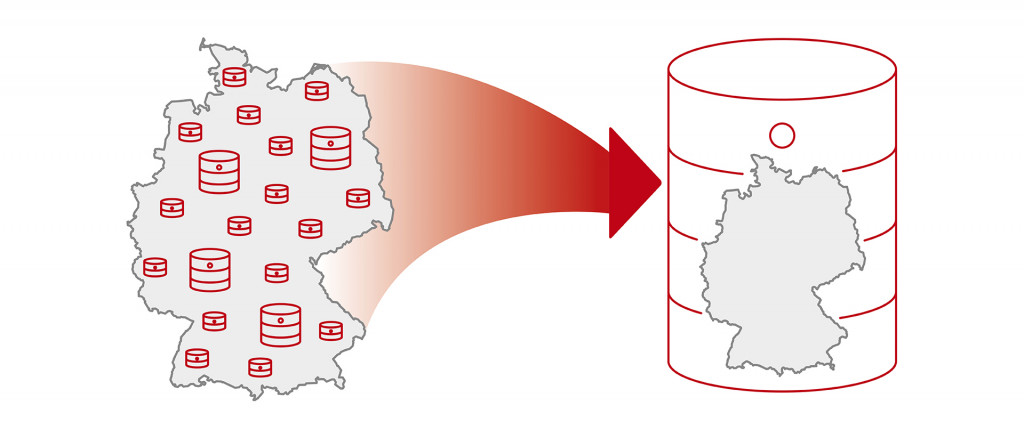
Ziel ist die Zusammenführung des dezentral und heterogen vorliegenden Datenbestands in einem zentralen und offenen Knowledge Graph für den Deutschlandtourismus, der von allen touristischen Akteuren und externen Dienstleistern gemeinschaftlich genutzt werden kann.
Graph-Datenbanken bilden die Basis, um solche situationsgerechten Antworten für Gäste liefern zu können. Aufgrund der Datenarchitektur in Form eines Netzwerks können einzelne Datenpunkte sehr gut zueinander in Beziehung gesetzt werden. So wie in der realen Welt ÖPNV, Veranstaltungsorte, Attraktionen (POI) oder Restaurants in einer Stadt mitein¬ander in Beziehung stehen, können diese Verbindungen auch in einer Graph-Datenbank dargestellt werden. Dabei muss nicht jede Beziehung neu programmiert werden, denn in Graph-Datenbanken ergeben sich Zusammenhänge bereits durch eine saubere Dateneingabe, bei der die Beziehungen explizit definiert werden. Zusätzlich ergeben sich Verknüpfungen neu eingepflegter Daten durch ihren Bezug zu bereits gespeicherten Daten, beispielsweise über deren Georeferenzierung (sogenanntes Geo-Reasoning).
Über Graph-Datenbanken können Beziehungen zwischen Daten sehr gut abgebildet werden.
Um eine derartige Funktionalität zu erreichen, müssen Daten eine entsprechende Qualität aufweisen und in einem solchen Knowledge Graph in Beziehung zueinander gesetzt werden. Zusätzliche Angaben wie Geokoordinaten sind dabei notwendig, um die Verbindung von einem Ausflugsziel zum nächstgelegenen Restaurant herzustellen. Das heißt, die Genauigkeit bei der Datenpflege gewinnt an Bedeutung. Ziel ist es, dass der in Deutschland dezentral und heterogen vorliegende touristische Datenbestand über einen Knowledge Graph verbunden wird.
Graph-Datenbanken in Abgrenzung zu relationalen Datenbanken
Mit dem Begriff der Datenbank werden oftmals Tabellen mit vielen Spalten und Zeilen assoziiert, die einer Excel-Tabelle ähneln. Derartige Datenbanken werden auch als relational bezeichnet, weil die einzelnen Tabellen über Relationen miteinander verknüpft werden können. Hierdurch wird es beispielsweise möglich, eine Verbindung zwischen einer Sehenswürdigkeit (POI) und nahe gelegenen Restaurants zu definieren. Derartige Beziehungen können in relationalen Datenbanken ausgebaut werden. Allerdings sind die Tabellen in sich starr und können nur umständlich geändert werden. Zudem führen sehr viele und mehrstufige Beziehungen (Relationen), die über das Verknüpfen von Tabellen entstehen, schnell zur Unübersichtlichkeit.
Graph-Datenbanken unterscheiden sich von relationalen Datenbanken in ihrer Struktur und in ihrem Aufbau. Sie werden in einer Netzwerkstruktur angelegt. Knoten (visuell als Punkte dargestellt) werden durch Kanten (dargestellt als Linien) miteinander verbunden. Die möglichen Verbindungen in dieser Netzwerkstruktur sind deutlich flexibler als in einer relationalen Datenbank. Daten und ihre Beziehung zueinander können angepasst und ausgetauscht werden, sodass flexible Veränderungen und Erweiterungen möglich sind.

Die unterschiedlichen Datenbestände der DMO sollen vereinheitlicht werden und zentral für alle zur Verfügung stehen.
Derzeit liegen touristische Daten weitestgehend in relationalen Datenbanken vor und dort in einzelnen Tabellen, die kaum in Beziehung miteinander gesetzt werden. Ziel ist es, diese Daten so aufzuarbeiten, dass sie einheitlich vorliegen, um so eine Verbindung von Inputs aus unterschiedlichen DMO herzustellen. Die Beziehung von Daten miteinander kann grundsätzlich auch in relationalen Datenbanken durch Verbindungen hergestellt werden. Dies wird jedoch schnell unübersichtlich, da Abfragen über mehrere Ebenen sehr komplex werden können. Graph-Datenbanken hingegen sind dafür ausgelegt, die Beziehung von Daten zueinander abzubilden. Die Datenarchitektur in Netzwerkstrukturen wird immer wichtiger, weil einheitlich beschriebene Daten und ihre Beziehung zueinander von Maschinen automatisch verstanden und weiterverarbeitet werden können, was eine wichtige Unterstützung für KI-Anwendungen ist. Auch Start-ups können diese Form der Datenhaltung sehr einfach entschlüsseln, wodurch sie direkt auf den Datenbestand zugreifen und innovative Ideen umsetzen können, ohne sich damit aufhalten zu müssen, die Logik der Beziehung der Daten zueinander umständlich zu entschlüsseln. Daher soll eine zentrale Graph-Datenbank für den Deutschlandtourismus entwickelt werden.
Google betreibt unter anderem eine solche Graph-Datenbank, die das Unternehmen „Knowledge Graph“ nennt, weil das Ziel darin besteht, über die Nutzung diverser Datenquellen kontextsensitive Antworten zu liefern. Google kann beispielsweise passende gastronomische Angebote oder Veranstaltungen entlang eines Wanderwegs anzeigen. Über den Zugriff auf diese Netzwerkstruktur der Daten können auch bessere Antworten für Sprachassistenten erzeugt werden. Der Nachteil dieses Knowledge Graph von Google: Er ist nicht offen zugänglich und wird nur von Google für die eigenen digitalen Anwendungen genutzt. Es kann somit nicht auf bereits bestehende Verknüpfungen innerhalb des Google-Universums zurückgegriffen werden.
Vorteile eines Knowledge Graph für den Deutschlandtourismus
Deshalb soll ein offener und unabhängiger Knowledge Graph für den Deutschlandtourismus etabliert werden. Touristische Akteure profitieren von der Bereitstellung der Daten in einem solchen Knowledge Graph durch die Verknüpfung mit anderen Daten. Es können beispielsweise, basierend auf Geodaten, Informationen über nahe gelegene Restaurants auf Wander- oder Radrouten ausgegeben und viele weitere Beziehungen zwischen diversen Daten hergestellt werden. Hierdurch wird eine überregionale Vernetzung im Knowledge Graph des Deutschlandtourismus etabliert, da die touristischen Daten aller teilnehmenden Akteure einheitlich ausgezeichnet und integriert werden. Somit sind Verbindungen von Daten bundesweit möglich, was beispielsweise dann interessant ist, wenn Touren sich über mehrere Bundesländer hinweg erstrecken.
Auf dieser Basis können reale und überregionale Kooperationen entstehen, durch die neue digitale Services für Gäste entwickelt werden. Diese umfangreichen Möglichkeiten zur Nutzung der Daten unterstützen auch eine Vorbereitung auf Anwendungen, die auf Künstlicher Intelligenz beruhen. Denn über die einheitliche Beschreibung der Daten mithilfe einer etablierten Ontologie wie schema.org und ihre Ablage in einer Netzwerkstruktur werden sowohl die Daten selbst als auch ihre Beziehungen zueinander maschinenlesbar. Dazu müssen nicht zwingend eigene Anwendungen entwickelt werden. Die Daten, die sich im Knowledge Graph des Deutschlandtourismus befinden, können außerdem genauso von Google genutzt werden wie auch von anderen externen Akteuren wie Mobilitätsanbietern usw. Ziel ist es, hierüber eine maximale Sichtbarkeit zu erreichen.
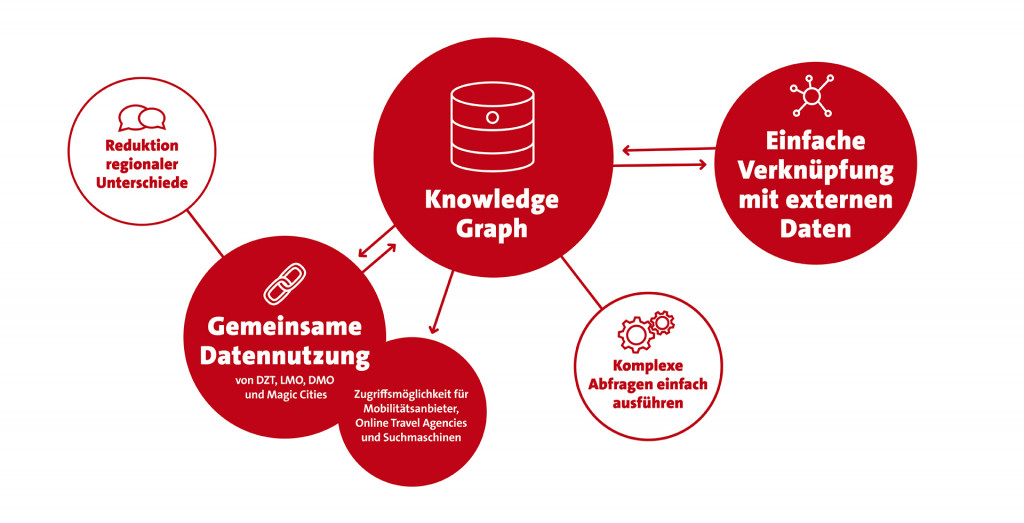
Der Knowledge Graph als Datenarchitektur der Zukunft
Anwendungen der Künstlichen Intelligenz (KI) wirken oft noch wie Science-Fiction. Aber sie werden schneller Standard sein, als es heute manchem vorstellbar erscheint. Deshalb ist es wichtig, jetzt schon die Datengrundlage dafür zu legen. Der Knowledge Graph spielt dabei für den Deutschlandtourismus eine wesentliche Rolle. Denn Künstliche Intelligenz ist in mehreren Punkten nicht mit der menschlichen Intelligenz vergleichbar. Konkret bedeutet dies:
Die Antworten und Vorhersagen, wie sie die genannten Beispiele liefern, können aus einem Knowledge Graph sehr gut extrahiert werden. Denn in Graph-Datenbanken können über Abfragen selbstständig sinnvolle Verknüpfungen (z. B. basierend auf der geografischen Lage) erstellt und auf der Grundlage von Erfahrungen angepasst werden. Nehmen Gäste bestimmte Angebote an, kann das System sich dank dieses Feedbacks immer feiner justieren und noch passgenauere Vorschläge machen. Bevor Maschinen jedoch autonom arbeiten können, benötigen sie eine gute Datenbasis. Die Daten sollten daher zum einen einheitlich ausgezeichnet sein und zum anderen in einer Netzwerkstruktur vorliegen. Ist dies der Fall, können sie über Algorithmen in jede erdenkliche Richtung abgefragt werden. Aus diesem Grund ist die technische Umsetzung des Knowledge Graph für den Deutschlandtourismus immer in Zusammenhang mit der Etablierung eines gemeinsamen Datenstandards zu sehen.
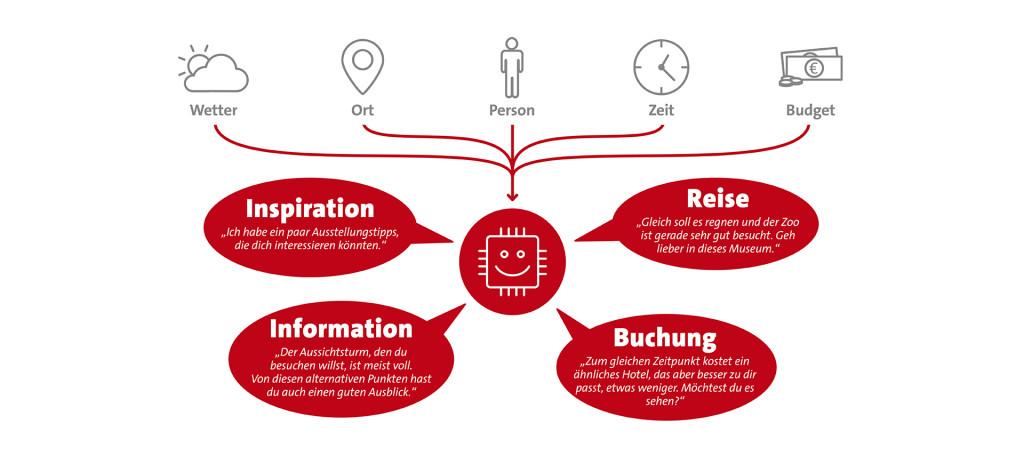
Die Daten in einem Knowledge Graph helfen dabei, automatisiert personalisierte Empfehlungen an Gäste zu geben.
Autonome Recommender verfolgen das Ziel, Touristen zu unterstützen, gleichzeitig besteht die Möglichkeit, sie in ihrem Verhalten zu beeinflussen. So können Vorhersagen (Predictive Analytics) und daraus abgeleitete persönliche Empfehlungen sowohl als digitaler Service für Gäste an der Destiantion bereitgestellt als auch als Instrument der Besucherlenkung genutzt werden.
Grundlage der Echtzeitempfehlungen kann der Datenbestand des Knowledge Graph für den Deutschlandtourismus sein. Seine Funktionen können zu einem autonomen Recommender als Urlaubsbegleitung zusammengeführt werden.

Eric Horster
Fachhochschule Westküste
Eric Horster ist Professor an der Fachhochschule Westküste im Bachelor- und Masterstudiengang International Tourism Management (ITM) mit den Schwerpunktfächern Digitalisierung im Tourismus und Hospitality Management. Er ist Mitglied des Deutschen Instituts für Tourismusforschung.
Mehr zur Person unter: www.eric-horster.de

Elias Kärle
Universität Innsbruck
Elias Kärle ist Wissenschaftler an der Universität Innsbruck. In seiner Forschung beschäftigt er sich mit Knowledge Graphs, Linked Data und Ontologien. Als Vortragender referiert er meist zur Anwendung und Verbreitung semantischer Technologien im Tourismus.
Mehr zur Person unter: https://elias.kaerle.com/